文 / 圖◎李志中教授、莊易璇同學
前言
當今,隨著人工智慧(AI)技術的迅速發展,電腦視覺(Computer Vision)領域也取得了顯著的進步。AI的深度學習模型已經變得越來越成熟,並且已應用到許多不同的領域。這些應用不僅改變了我們的生活方式,也推動了各個行業的進步。例如,自動駕駛汽車利用電腦視覺來識別道路標誌、行人和其他車輛;醫療影像分析可以幫助醫生檢測和診斷疾病;零售業則使用電腦視覺技術來監控庫存和提升顧客服務;工廠生產也將電腦視覺技術結合機械手臂,完成高重複性的工作。而現在,AI也讓機械手臂變得更加聰明,不僅能準確識別物體,甚至能像人類一樣靈活地夾取並擺放物品。這些應用展示了AI在電腦視覺領域的強大潛力和廣泛用途。
傳統電腦視覺技術
在AI技術還沒有普遍之前,傳統的電腦視覺任務主要依賴各種數學演算法來完成。對於電腦來說,一張512x512的影像是一個包含262,144個像素的矩陣,每個像素都有不同的數值來表示其色彩和亮度。這些數值的變化和組合構成了我們所看到的圖像內容。
首先,邊緣偵測是傳統電腦視覺中的一個重要方法,用來找出圖像中物體的輪廓。Sobel邊緣偵測算法[1]就是其中一個常見的方法,就像畫畫時用鉛筆描邊,讓物體輪廓更清晰。這種算法通過應用一組濾波器矩陣與原影像作矩陣乘法運算,來強調圖像中亮度變化最明顯的區域,這些區域通常是物體的邊緣,如下圖1所示。


█ 圖1 邊緣偵測示意圖
上圖:原圖;下圖:經偵測算法之邊緣
接著,分割物體則是將圖像中不同物件類別的區域區分開來,可以使用如區域增長或K-means聚類等技術。此外,特徵提取是從影像中取出能夠代表影像關鍵訊息的數據,例如:顏色、邊緣、角點、紋理等,可以幫助電腦「理解」影像內容。尺度不變特徵變換(Scale-Invariant Feature Transform, SIFT)[2] 是一種常見的方法,類似於指紋辨識,能找出圖像中特定的關鍵點並進行比對。它會分析影像中不同區域的特徵,計算關鍵點的方向與強度,進而建立一組獨特的「特徵指紋」,讓電腦能夠辨識並匹配相似的圖像,如下圖 2 所示。因此,此一方法也常用於場景物件的姿態辨識。最後,形狀識別則是根據物體的輪廓或特徵來識別它們,這可以通過霍夫變換等技術來實現,特別適用於檢測圖像中的直線或圓形等幾何形狀。這些傳統方法在一定程度上能夠解決電腦視覺中的基本問題,但相較於現今的AI技術,精確度和適應性仍存在許多限制。
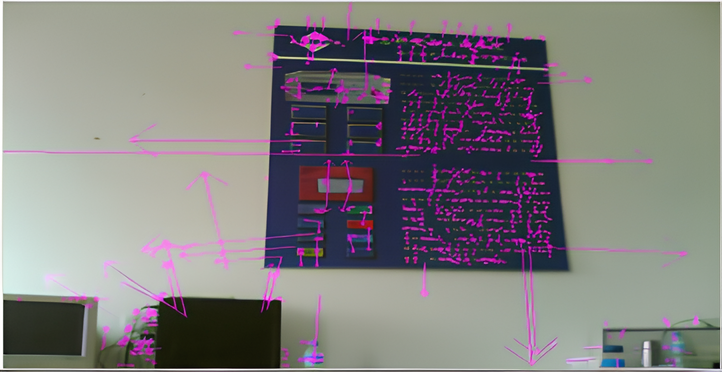

█ 圖2 SIFT演算法計算梯度與特徵匹配[3]
█ 上圖:影像特徵圖,箭頭方向代表特徵點梯度方向;下圖:相同特徵匹配圖
AI在機械手臂撿貨的應用
機器人為什麼要學會夾取?試想一下,在工廠或物流倉庫中,工人每天都要搬運大量物件,這不僅耗費體力,長時間下來也容易產生疲勞。如果機械手臂能夠準確地抓取並擺放物品,不僅能減少人力負擔,也能大幅提升作業效率。隨著AI科技的進步,機器人學習夾取的方式也變得更加聰明。目前,機械手臂的夾取任務主要可以透過兩種方法來實現:端到端(End-to-End)模型和模組化流程。端到端模型是一種只需使用一個深度學習模型就能直接得到最終夾取位置的方法,雖然簡化了流程,但缺點是訓練該模型通常需要大量標註夾取點位置的數據而且場景一旦改變,整個模型可能需要重新訓練。早期,Pinto[4] 透過自我監督學習(Self-supervised Learning),讓機器人透過大量試誤自行學習抓取策略,他們的研究讓機器人自主嘗試 50,000 次抓取,累積 700 小時收集物件夾取點數據,可見得此一方法所耗費之資源龐大。模組化流程則是將機器手臂撿貨的任務分解成多個步驟,每個步驟分別由不同的模型來完成。這樣,每個步驟都可以針對特定任務進行優化,以確保整個流程的彈性與穩定性。以下我們介紹一個簡易的模組化流程,如圖3所示,可以容易地實現機械手臂夾取堆疊物件的目的。
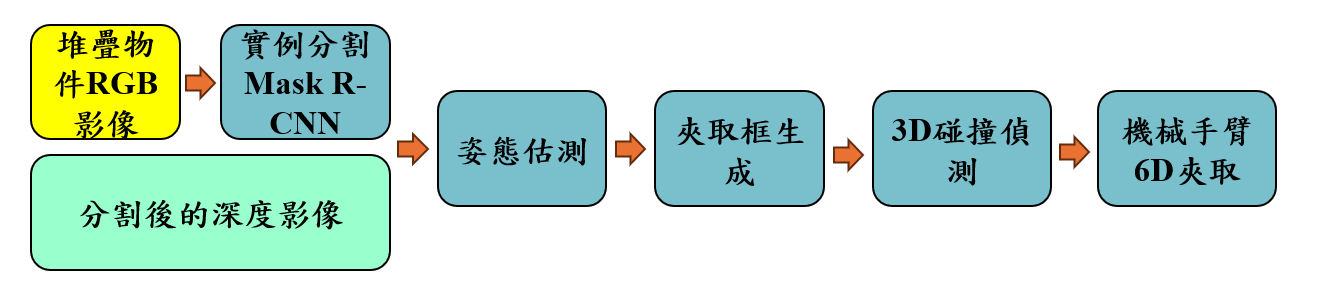
█ 圖3 簡易機械手臂夾取堆疊物件流程
首先,我們會用相機對堆疊物件的場景進行拍照,結果如圖4(a)所示。這一步是整個過程的基礎,因為所有後續的分析都依賴於這些圖像。接著,我們會使用實例分割(Instance segmentation)的模型,如Mask R-CNN網路模型來將每一個物體的圖像分割出來,並框選出它們的位置,同時識別出每個物體的類別,如圖4(b)所示。這一步有點像是讓電腦「看見」並「認出」每一個物體。實例分割模型能夠精確地區分出每個物體,即使它們互相重疊或者顏色相似。當然,在此之前,需要拍許多堆疊物件場景的圖像來訓練一個好的Mask R-CNN網路模型。不過幸運的是,目前已經可以利用像Blender的電腦圖形軟體自動產生許多合成且標註好的圖像用來訓練Mask R-CNN網路模型,不需要以人工去標註每一張圖像中的物件。接下來,我們會使用姿態估測模型來預測每個物體在場景中的位置與方向,如圖4(c)。這一步就像是告訴機械手臂每個物體「在哪裡」以及它的姿態,這樣機械手臂才能準確地去夾取它們。姿態估測模型不僅能夠確定物體的三維位置,還能夠估計它們的姿態角度,例如常用於描述物體姿態的歐拉角,這對於精確夾取非常重要。姿態估測的模型有很多,例如AutoEncoder、DenseFusion和PPR-Net等。
最後,我們需要選擇合適的夾取位置,如圖4(d)所示,綠色方框為夾爪可下落的位置。這一步非常重要,因為我們要確保機械手臂在夾取物體時不會碰到旁邊的物體或和底部發生碰撞。這個過程需要考慮多種因素,如物體之間的距離、夾爪的大小和形狀等,細節可以參考[5]。我們會篩選出一個最佳的夾取位置,這樣機械手臂就可以順利完成夾取任務。當然,在此之前的前置工作是將每一種物件可行的夾取位置預先設好。以T形管為例(見圖5中的左圖),在不同姿態下標註的夾取框(綠色矩形),如中間的兩張圖所示。右圖顯示了該物件所有可行的夾取框。這些可行的夾取框可從人手拾取該物的經驗中獲得,因此可以隨時修正。

█ 圖4 隨機堆疊物件夾取步驟圖 (a)輸入影像 (b)實例分割結果 (c)姿態估測結果 (d)標示出夾取框
機械手臂實際夾取影片連結:https://youtu.be/LDHmKGCPOMo?feature=shared

█ 圖5 目標物件姿態與標註之夾取框
█ 左: T形管 中間二圖: 該視角下的物件之夾取框 右: 所有夾取框
結論
透過以上的介紹,我們可以看到,AI技術在電腦視覺領域的應用已經大大超越了傳統算法的效果。它不僅提升了任務的準確性和效率,還實現了許多過去難以想像的應用,例如自動駕駛、醫療影像分析、零售監控及工業自動化生產等,展現出強大的能力與廣泛的應用前景。
然而,現階段的技術仍然面臨一些挑戰。例如,機械手臂在抓取形狀不規則或材質特殊的物體時,可能因夾取點的選擇不佳而導致失敗。此外,外部環境的變化,如光線不足或反光干擾,仍可能影響電腦視覺的準確性。如何讓技術更加穩定、靈活,以適應更複雜的場景,仍是未來需要克服的難題。
隨著自適應機械手臂、多模態感知系統以及更高效深度學習模型的發展,我們可以期待未來的突破讓機器人更加智能,應用範圍更加廣泛。無論是災難救援、醫療輔助,還是太空探索,這些技術的進步將不斷改變我們的生活方式,帶來更多革命性的變化,讓未來更加便利與充滿可能性。
參考文獻
[1] Vincent, O. R., Folorunso, O., “A Descriptive Algorithm for Sobel Image Edge Detection,” Proceedings of informing science & IT education conference (InSITE). Vol. 40. 2009.
[2] Lowe, D. G., “Object recognition from local scale-invariant features,” Proceedings of International Conference on Computer Vision, vol. 2, no. 9, pp. 1150-1157, 1999.
[3] Hua, Y., Lin, J., and Lin, C., “An Improved SIFT Feature Matching Algorithm,” 2010 8th World Congress on Intelligent Control and Automation, Jinan, China, 2010, pp. 6109-6113.
[4] Pinto L. and Gupta, A., “Supersizing self-supervision: Learning to grasp from 50K tries and 700 robot hours,” 2016 IEEE International Conference on Robotics and Automation, 2016, pp. 3406-3413.
[5] 莊易璇,應用融合RGB和點雲於堆疊物件六自由度夾取之優化,碩士論文,國立臺灣大學機械系,台北市,台灣,2024。